LeoBringer
MDMP: Multimodal Diffusion model for Motion Prediction with uncertainty
ArXiv
Website Page
Code
Human Motion Forecasting for Dynamic Human-Robot Collaboration
Report
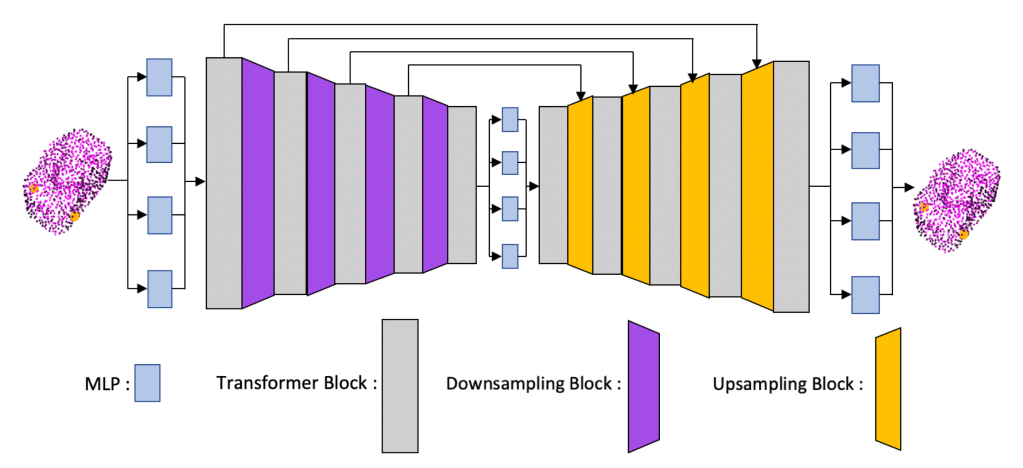
Point Transformer based Auto-Encoder for Robot Grasping
Using Computer Vision to ensure safety in Human-Robot Collaboration